¿Qué es RAID?
El término RAID es un acrónimo del inglés "Redundant Array of Independent Disks". Significa matriz redundante de discos independientes. RAID es un método de combinación de varios discos duros para formar una única unidad lógica en la que se almacenan los datos de forma redundante. Ofrece mayor tolerancia a fallos y más altos niveles de rendimiento que un sólo disco duro o un grupo de discos duros independientes. Una matriz consta de dos o más discos duros que ante el sistema principal funcionan como un único dispositivo. Un RAID, para el sistema operativo, aparenta ser un sólo disco duro lógico (LUN). Los datos se desglosan en fragmentos que se escriben en varias unidades de forma simultánea. En este método, la información se reparte entre varios discos, usando técnicas como el entrelazado de bloques (RAID nivel 0) o la duplicación de discos (RAID nivel 1) para proporcionar redundancia, reducir el tiempo de acceso, y/o obtener mayor ancho de banda para leer y/o escribir, así como la posibilidad de recuperar un sistema tras la avería de uno de los discos.
La tecnología RAID protege los datos contra el fallo de una unidad de disco duro. Si se produce un fallo, RAID mantiene el servidor activo y en funcionamiento hasta que se sustituya la unidad defectuosa.
La tecnología RAID se utiliza también con mucha frecuencia para mejorar el rendimiento de servidores y estaciones de trabajo. Estos dos objetivos, protección de datos y mejora del rendimiento, no se excluyen entre sí.
RAID ofrece varias opciones, llamadas niveles RAID, cada una de las cuales proporciona un equilibrio distinto entre tolerancia a fallos, rendimiento y coste.
Todos los sistemas RAID suponen la pérdida de parte de la capacidad de almacenamiento de los discos, para conseguir la redundancia o almacenar los datos de paridad.
Los sistemas RAID profesionales deben incluir los elementos críticos por duplicado: fuentes de alimentación y ventiladores redundantes y Hot Swap. De poco sirve disponer de un sistema tolerante al fallo de un disco si después falla por ejemplo una fuente de alimentación que provoca la caída del sistema.
También cada vez es más recomendable, sobre todo en instalaciones de cluster, configuraciones de dos controladoras redundantes y Hot Swap, de manera que en el caso de fallo de una de ellas se puede proceder a su sustitución sin tener que detener el funcionamiento del sistema. Además, esta configuración con controladoras redundantes nos permite conectar el sistema RAID a diferentes servidores simultáneamente.
Ventajas de RAID
RAID proporciona tolerancia a fallos, mejora el rendimiento del sistema y aumenta la productividad.
Tolerancia a fallos: RAID protege contra la pérdida de datos y proporciona recuperación de datos en tiempo real con acceso interrumpido en caso de que falle un disco.
Mejora del Rendimiento/ Velocidad: Una matriz consta de dos o más discos duros que ante el sistema principal funcionan como un único dispositivo. Los datos se desglosan en fragmentos que se escriben en varias unidades de forma simultánea. Este proceso, denominado fraccionamiento de datos, incrementa notablemente la capacidad de almacenamiento y ofrece mejoras significativas de rendimiento. RAID permite a varias unidades trabajar en paralelo, lo que aumenta el rendimiento del sistema.
Mejora del Rendimiento/ Velocidad: Una matriz consta de dos o más discos duros que ante el sistema principal funcionan como un único dispositivo. Los datos se desglosan en fragmentos que se escriben en varias unidades de forma simultánea. Este proceso, denominado fraccionamiento de datos, incrementa notablemente la capacidad de almacenamiento y ofrece mejoras significativas de rendimiento. RAID permite a varias unidades trabajar en paralelo, lo que aumenta el rendimiento del sistema.
Mayor Fiabilidad: Las soluciones RAID emplean dos técnicas para aumentar la fiabilidad: la redundancia de datos y la información de paridad. La redundancia implica el almacenamiento de los mismos datos en más de una unidad. De esta forma, si falla una unidad, todos los datos quedan disponibles en la otra unidad, de inmediato. Aunque este planteamiento es muy eficaz, también es muy costoso, ya que exige el uso de conjuntos de unidades duplicados. El segundo planteamiento para la protección de los datos consiste en el uso de la paridad de datos. La paridad utiliza un algoritmo matemático para describir los datos de una unidad. Cuando se produce un fallo en una unidad se leen los datos correctos que quedan y se comparan con los datos de paridad almacenados por la matriz. El uso de la paridad para obtener fiabilidad de los datos es menos costoso que la redundancia, ya que no requiere el uso de un conjunto redundante de unidades de disco.
Alta Disponibilidad: RAID aumenta el tiempo de funcionamiento y la disponibilidad de la red. Para evitar los tiempos de inactividad, debe ser posible acceder a los datos en cualquier momento. La disponibilidad de los datos se divide en dos aspectos: la integridad de los datos y tolerancia a fallos. La integridad de los datos se refiere a la capacidad para obtener los datos adecuados en cualquier momento. La mayoría de las soluciones RAID ofrecen reparación dinámica de sectores, que repara sobre la marcha los sectores defectuosos debidos a errores de software. La tolerancia a fallos, el segundo aspecto de la disponibilidad, es la capacidad para mantener los datos disponibles en caso de que se produzcan uno o varios fallos en el sistema.
Niveles
RAID estándar
Los niveles RAID más comúnmente usados son:- RAID 0: Conjunto dividido
- RAID 1: Conjunto en espejo
- RAID 5: Conjunto dividido con paridad distribuida
{kind=link}
Un RAID 1 crea una copia exacta (o espejo) de un conjunto de datos en dos o más discos. Esto resulta útil cuando el rendimiento en lectura es más importante que la capacidad. Un conjunto RAID 1 sólo puede ser tan grande como el más pequeño de sus discos. Un RAID 1 clásico consiste en dos discos en espejo, lo que incrementa exponencialmente la fiabilidad respecto a un solo disco; es decir, la probabilidad de fallo del conjunto es igual al producto de las probabilidades de fallo de cada uno de los discos (pues para que el conjunto falle es necesario que lo hagan todos sus discos).
Adicionalmente, dado que todos los datos están en dos o más discos, con hardware habitualmente independiente, el rendimiento de lectura se incrementa aproximadamente como múltiplo lineal del número del copias; es decir, un RAID 1 puede estar leyendo simultáneamente dos datos diferentes en dos discos diferentes, por lo que su rendimiento se duplica. Para maximizar los beneficios sobre el rendimiento del RAID 1 se recomienda el uso de controladoras de disco independientes, una para cada disco (práctica que algunos denominan splitting o duplexing).
Como en el RAID 0, el tiempo medio de lectura se reduce, ya que los sectores a buscar pueden dividirse entre los discos, bajando el tiempo de búsqueda y subiendo la tasa de transferencia, con el único límite de la velocidad soportada por la controladora RAID. Sin embargo, muchas tarjetas RAID 1 IDE antiguas leen sólo de un disco de la pareja, por lo que su rendimiento es igual al de un único disco. Algunas implementaciones RAID 1 antiguas también leen de ambos discos simultáneamente y comparan los datos para detectar errores. La detección y corrección de errores en los discos duros modernos hacen esta práctica poco útil.
Al escribir, el conjunto se comporta como un único disco, dado que los datos deben ser escritos en todos los discos del RAID 1. Por tanto, el rendimiento no mejora.
El RAID 1 tiene muchas ventajas de administración. Por ejemplo, en algunos entornos 24/7, es posible «dividir el espejo»: marcar un disco como inactivo, hacer una copia de seguridad de dicho disco y luego «reconstruir» el espejo. Esto requiere que la aplicación de gestión del conjunto soporte la recuperación de los datos del disco en el momento de la división. Este procedimiento es menos crítico que la presencia de una característica de snapshot en algunos sistemas de ficheros, en la que se reserva algún espacio para los cambios, presentando una vista estática en un punto temporal dado del sistema de ficheros. Alternativamente, un conjunto de discos puede ser almacenado de forma parecida a como se hace con las tradicionales cintas.

RAID 2
Teóricamente, un RAID 2 necesitaría 39 discos en un sistema informático moderno: 32 se usarían para almacenar los bits individuales que forman cada palabra y 7 se usarían para la corrección de errores.

RAID 3
En el ejemplo del gráfico, una petición del bloque «A» formado por los bytes A1 a A6 requeriría que los tres discos de datos buscaran el comienzo (A1) y devolvieran su contenido. Una petición simultánea del bloque «B» tendría que esperar a que la anterior concluyese.

RAID 4
Un RAID 4 usa división a nivel de bloques con un disco de paridad dedicado. Necesita un mínimo de 3 discos físicos. El RAID 4 es parecido al RAID 3 excepto porque divide a nivel de bloques en lugar de a nivel de bytes. Esto permite que cada miembro del conjunto funcione independientemente cuando se solicita un único bloque. Si la controladora de disco lo permite, un conjunto RAID 4 puede servir varias peticiones de lectura simultáneamente. En principio también sería posible servir varias peticiones de escritura simultáneamente, pero al estar toda la información de paridad en un solo disco, éste se convertiría en el cuello de botella del conjunto.En el gráfico de ejemplo anterior, una petición del bloque «A1» sería servida por el disco 0. Una petición simultánea del bloque «B1» tendría que esperar, pero una petición de «B2» podría atenderse concurrentemente.

RAID 5
En el gráfico de ejemplo anterior, una petición de lectura del bloque «A1» sería servida por el disco 0. Una petición de lectura simultánea del bloque «B1» tendría que esperar, pero una petición de lectura de «B2» podría atenderse concurrentemente ya que seria servida por el disco 1.
Cada vez que un bloque de datos se escribe en un RAID 5, se genera un bloque de paridad dentro de la misma división (stripe). Un bloque se compone a menudo de muchos sectores consecutivos de disco. Una serie de bloques (un bloque de cada uno de los discos del conjunto) recibe el nombre colectivo de división (stripe). Si otro bloque, o alguna porción de un bloque, es escrita en esa misma división, el bloque de paridad (o una parte del mismo) es recalculada y vuelta a escribir. El disco utilizado por el bloque de paridad está escalonado de una división a la siguiente, de ahí el término «bloques de paridad distribuidos». Las escrituras en un RAID 5 son costosas en términos de operaciones de disco y tráfico entre los discos y la controladora.
Los bloques de paridad no se leen en las operaciones de lectura de datos, ya que esto sería una sobrecarga innecesaria y disminuiría el rendimiento. Sin embargo, los bloques de paridad se leen cuando la lectura de un sector de datos provoca un error de CRC. En este caso, el sector en la misma posición relativa dentro de cada uno de los bloques de datos restantes en la división y dentro del bloque de paridad en la división se utilizan para reconstruir el sector erróneo. El error CRC se oculta así al resto del sistema. De la misma forma, si falla un disco del conjunto, los bloques de paridad de los restantes discos son combinados matemáticamente con los bloques de datos de los restantes discos para reconstruir los datos del disco que ha fallado «al vuelo».
Lo anterior se denomina a veces Modo Interino de Recuperación de Datos (Interim Data Recovery Mode). El sistema sabe que un disco ha fallado, pero sólo con el fin de que el sistema operativo pueda notificar al administrador que una unidad necesita ser reemplazada: las aplicaciones en ejecución siguen funcionando ajenas al fallo. Las lecturas y escrituras continúan normalmente en el conjunto de discos, aunque con alguna degradación de rendimiento. La diferencia entre el RAID 4 y el RAID 5 es que, en el Modo Interno de Recuperación de Datos, el RAID 5 puede ser ligeramente más rápido, debido a que, cuando el CRC y la paridad están en el disco que falló, los cálculos no tienen que realizarse, mientras que en el RAID 4, si uno de los discos de datos falla, los cálculos tienen que ser realizados en cada acceso.
El RAID 5 requiere al menos tres unidades de disco para ser implementado. El fallo de un segundo disco provoca la pérdida completa de los datos.
El número máximo de discos en un grupo de redundancia RAID 5 es teóricamente ilimitado, pero en la práctica es común limitar el número de unidades. Los inconvenientes de usar grupos de redundancia mayores son una mayor probabilidad de fallo simultáneo de dos discos, un mayor tiempo de reconstrucción y una mayor probabilidad de hallar un sector irrecuperable durante una reconstrucción. A medida que el número de discos en un conjunto RAID 5 crece, el MTBF (tiempo medio entre fallos) puede ser más bajo que el de un único disco. Esto sucede cuando la probabilidad de que falle un segundo disco en los N-1 discos restantes de un conjunto en el que ha fallado un disco en el tiempo necesario para detectar, reemplazar y recrear dicho disco es mayor que la probabilidad de fallo de un único disco. Una alternativa que proporciona una protección de paridad dual, permitiendo así mayor número de discos por grupo, es el RAID 6.
Algunos vendedores RAID evitan montar discos de los mismos lotes en un grupo de redundancia para minimizar la probabilidad de fallos simultáneos al principio y el final de su vida útil.
Las implementaciones RAID 5 presentan un rendimiento malo cuando se someten a cargas de trabajo que incluyen muchas escrituras más pequeñas que el tamaño de una división (stripe). Esto se debe a que la paridad debe ser actualizada para cada escritura, lo que exige realizar secuencias de lectura, modificación y escritura tanto para el bloque de datos como para el de paridad. Implementaciones más complejas incluyen a menudo cachés de escritura no volátiles para reducir este problema de rendimiento.
En el caso de un fallo del sistema cuando hay escrituras activas, la paridad de una división (stripe) puede quedar en un estado inconsistente con los datos. Si esto no se detecta y repara antes de que un disco o bloque falle, pueden perderse datos debido a que se usará una paridad incorrecta para reconstruir el bloque perdido en dicha división. Esta potencial vulnerabilidad se conoce a veces como «agujero de escritura». Son comunes el uso de caché no volátiles y otras técnicas para reducir la probabilidad de ocurrencia de esta vulnerabilidad.

RAID 6
El RAID 6 puede ser considerado un caso especial de código Reed-Solomon.[1] El RAID 6, siendo un caso degenerado, exige sólo sumas en el campo de Galois.[2] Dado que se está operando sobre bits, lo que se usa es un campo binario de Galois (
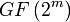 ). En las representaciones cíclicas de los campos binarios de Galois, la suma se calcula con un simple XOR.
). En las representaciones cíclicas de los campos binarios de Galois, la suma se calcula con un simple XOR.Tras comprender el RAID 6 como caso especial de un código Reed-Solomon, se puede ver que es posible ampliar este enfoque para generar redundancia simplemente produciendo otro código, típicamente un polinomio en
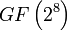 (m = 8 significa que estamos operando sobre bytes). Al añadir códigos adicionales es posible alcanzar cualquier número de discos redundantes, y recuperarse de un fallo de ese mismo número de discos en cualquier puntos del conjunto, pero en el nivel RAID 6 se usan dos únicos códigos.
(m = 8 significa que estamos operando sobre bytes). Al añadir códigos adicionales es posible alcanzar cualquier número de discos redundantes, y recuperarse de un fallo de ese mismo número de discos en cualquier puntos del conjunto, pero en el nivel RAID 6 se usan dos únicos códigos.Al igual que en el RAID 5, en el RAID 6 la paridad se distribuye en divisiones (stripes), con los bloques de paridad en un lugar diferente en cada división.
El RAID 6 es ineficiente cuando se usa un pequeño número de discos pero a medida que el conjunto crece y se dispone de más discos la pérdida en capacidad de almacenamiento se hace menos importante, creciendo al mismo tiempo la probabilidad de que dos discos fallen simultáneamente. El RAID 6 proporciona protección contra fallos dobles de discos y contra fallos cuando se está reconstruyendo un disco. En caso de que sólo tengamos un conjunto puede ser más adecuado que usar un RAID 5 con un disco de reserva (hot spare).
La capacidad de datos de un conjunto RAID 6 es n-2, siendo n el número total de discos del conjunto.
Un RAID 6 no penaliza el rendimiento de las operaciones de lectura, pero sí el de las de escritura debido al proceso que exigen los cálculos adicionales de paridad. Esta penalización puede minimizarse agrupando las escrituras en el menor número posible de divisiones (stripes), lo que puede lograrse mediante el uso de un sistema de ficheros WAFL.

RAID 5E y RAID 6E

Niveles RAID anidados
Muchas controladoras permiten anidar niveles RAID, es decir, que un RAID pueda usarse como elemento básico de otro en lugar de discos físicos. Resulta instructivo pensar en estos conjuntos como capas dispuestas unas sobre otras, con los discos físicos en la inferior.Los RAID anidados se indican normalmente uniendo en un solo número los correspondientes a los niveles RAID usados, añadiendo a veces un «+» entre ellos. Por ejemplo, el RAID 10 (o RAID 1+0) consiste conceptualmente en múltiples conjuntos de nivel 1 almacenados en discos físicos con un nivel 0 encima, agrupando los anteriores niveles 1. En el caso del RAID 0+1 se usa más esta forma que RAID 01 para evitar la confusión con el RAID 1. Sin embargo, cuando el conjunto de más alto nivel es un RAID 0 (como en el RAID 10 y en el RAID 50), la mayoría de los vendedores eligen omitir el «+», a pesar de que RAID 5+0 sea más informativo.
Al anidar niveles RAID, se suele combinar un nivel RAID que proporcione redundancia con un RAID 0 que aumenta el rendimiento. Con estas configuraciones es preferible tener el RAID 0 como nivel más alto y los conjuntos redundantes debajo, porque así será necesario reconstruir menos discos cuando uno falle. (Así, el RAID 10 es preferible al RAID 0+1 aunque las ventajas administrativas de «dividir el espejo» del RAID 1 se perderían.)
Los niveles RAID anidados más comúnmente usados son:
- RAID 0+1: Un espejo de divisiones
- RAID 1+0: Una división de espejos
- RAID 30: Una división de niveles RAID con paridad dedicada
- RAID 100: Una división de una división de espejos
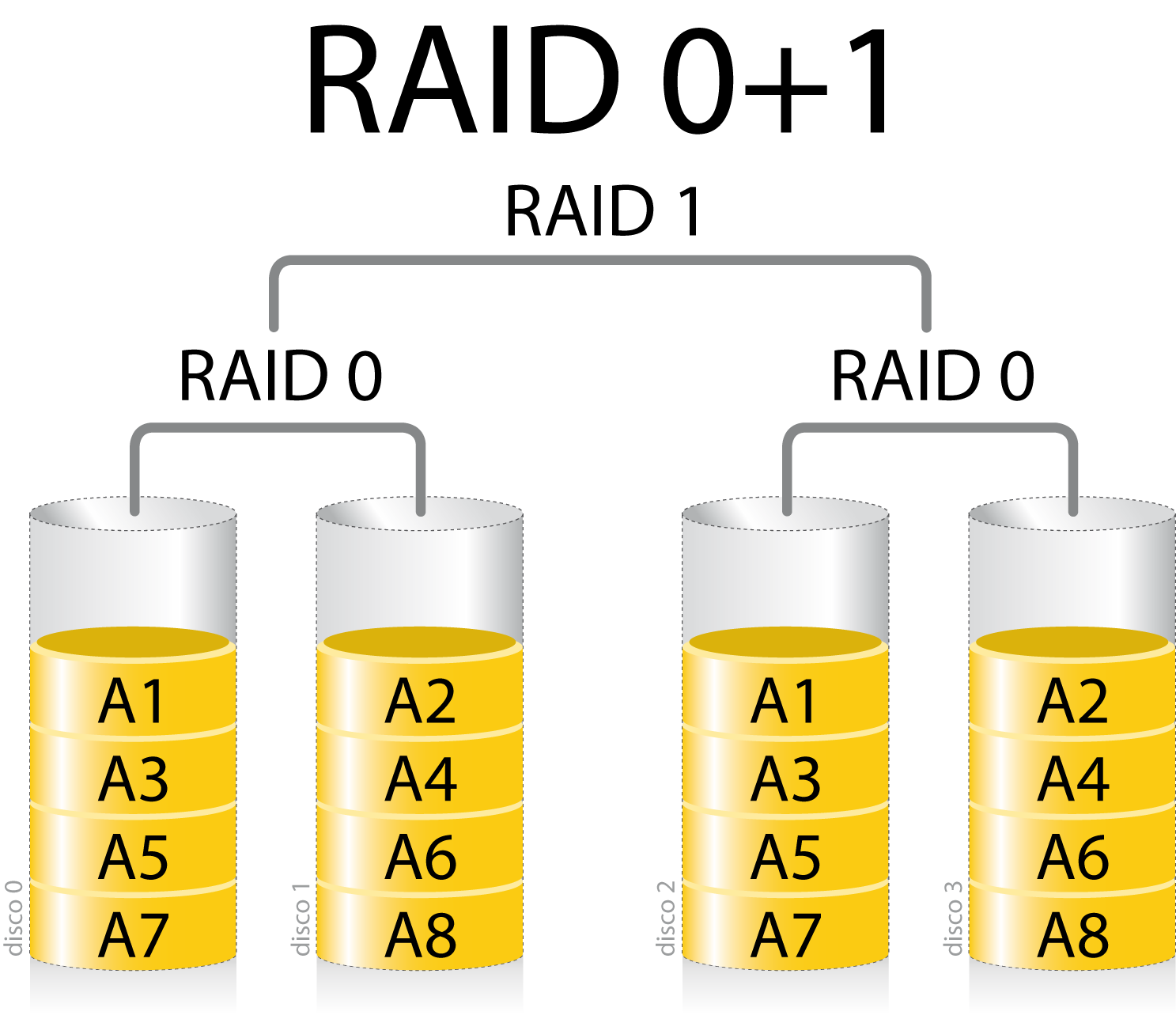
RAID 0+1
Un RAID 0+1 (también llamado RAID 01, que no debe confundirse con RAID 1) es un RAID usado para replicar y compartir datos entre varios discos. La diferencia entre un RAID 0+1 y un RAID 1+0 es la localización de cada nivel RAID dentro del conjunto final: un RAID 0+1 es un espejo de divisiones.Como puede verse en el diagrama, primero se crean dos conjuntos RAID 0 (dividiendo los datos en discos) y luego, sobre los anteriores, se crea un conjunto RAID 1 (realizando un espejo de los anteriores). La ventaja de un RAID 0+1 es que cuando un disco duro falla, los datos perdidos pueden ser copiados del otro conjunto de nivel 0 para reconstruir el conjunto global. Sin embargo, añadir un disco duro adicional en una división, es obligatorio añadir otro al de la otra división para equilibrar el tamaño del conjunto.
Además, el RAID 0+1 no es tan robusto como un RAID 1+0, no pudiendo tolerar dos fallos simultáneos de discos salvo que sean en la misma división. Es decir, cuando un disco falla, la otra división se convierte en un punto de fallo único. Además, cuando se sustituye el disco que falló, se necesita que todos los discos del conjunto participen en la reconstrucción de los datos.
Con la cada vez mayor capacidad de las unidades de discos (liderada por las unidades serial ATA), el riesgo de fallo de los discos es cada vez mayor. Además, las tecnologías de corrección de errores de bit no han sido capaces de mantener el ritmo de rápido incremento de las capacidades de los discos, provocando un mayor riesgo de hallar errores físicos irrecuperables.
Dados estos cada vez mayores riesgos del RAID 0+1 (y su vulnerabilidad ante los fallos dobles simultáneos), muchos entornos empresariales críticos están empezando a evaluar configuraciones RAID más tolerantes a fallos que añaden un mecanismo de paridad subyacente. Entre los más prometedores están los enfoques híbridos como el RAID 0+1+5 (espejo sobre paridad única) o RAID 0+1+6 (espejo sobre paridad dual). Son los más habituales por las empresas.
RAID 1+0
En cada división RAID 1 pueden fallar todos los discos salvo uno sin que se pierdan datos. Sin embargo, si los discos que han fallado no se reemplazan, el restante pasa a ser un punto único de fallo para todo el conjunto. Si ese disco falla entonces, se perderán todos los datos del conjunto completo. Como en el caso del RAID 0+1, si un disco que ha fallado no se reemplaza, entonces un solo error de medio irrecuperable que ocurra en el disco espejado resultaría en pérdida de datos.
Debido a estos mayores riesgos del RAID 1+0, muchos entornos empresariales críticos están empezando a evaluar configuraciones RAID más tolerantes a fallos que añaden un mecanismo de paridad subyacente. Entre los más prometedores están los enfoques híbridos como el RAID 0+1+5 (espejo sobre paridad única) o RAID 0+1+6 (espejo sobre paridad dual).
El RAID 10 es a menudo la mejor elección para bases de datos de altas prestaciones, debido a que la ausencia de cálculos de paridad proporciona mayor velocidad de escritura.

RAID 30
El RAID 30 permite que falle un disco de cada conjunto RAID 3. Hasta que estos discos que fallaron sean reemplazados, los otros discos de cada conjunto que sufrió el fallo son puntos únicos de fallo para el conjunto RAID 30 completo. En otras palabras, si alguno de ellos falla se perderán todos los datos del conjunto. El tiempo de recuperación necesario (detectar y responder al fallo del disco y reconstruir el conjunto sobre el disco nuevo) representa un periodo de vulnerabilidad para el RAID.

RAID 100
Todos los discos menos unos podrían fallar en cada RAID 1 sin perder datos. Sin embargo, el disco restante de un RAID 1 se convierte así en un punto único de fallo para el conjunto degradado. A menudo el nivel superior de división se hace por software. Algunos vendedores llaman a este nivel más alto un MetaLun o Soft Stripe..
Los principales beneficios de un RAID 100 (y de los RAID cuadriculados en general) sobre un único nivel RAID son mejor rendimiento para lecturas aleatorias y la mitigación de los puntos calientes de riesgo en el conjunto. Por estas razones, el RAID 100 es a menudo la mejor elección para bases de datos muy grandes, donde el conjunto software subyacente limita la cantidad de discos físicos permitidos en cada conjunto estándar. Implementar niveles RAID anidados permite eliminar virtualmente el límite de unidades físicas en un único volumen lógico.

RAID 50
Un disco de cada conjunto RAID 5 puede fallar sin que se pierdan datos. Sin embargo, si el disco que falla no se reemplaza, los discos restantes de dicho conjunto se convierten en un punto único de fallo para todo el conjunto. Si uno falla, todos los datos del conjunto global se pierden. El tiempo necesario para recuperar (detectar y responder al fallo de disco y reconstruir el conjunto sobre el nuevo disco) representa un periodo de vulnerabilidad del conjunto RAID.
La configuración de los conjuntos RAID repercute sobre la tolerancia a fallos general. Una configuración de tres conjuntos RAID 5 de siete discos cada uno tiene la mayor capacidad y eficiencia de almacenamiento, pero sólo puede tolerar un máximo de tres fallos potenciales de disco. Debido a que la fiabilidad del sistema depende del rápido reemplazo de los discos averiados para que el conjunto pueda reconstruirse, es común construir conjuntos RAID 5 de seis discos con un disco de reserva en línea (hot spare) que permite empezar de inmediato la reconstrucción en caso de fallo del conjunto. Esto no soluciona el problema de que el conjunto sufre un estrés máximo durante la reconstrucción dado que es necesario leer cada bit, justo cuando es más vulnerable. Una configuración de siete conjuntos RAID 5 de tres discos cada uno puede tolerar hasta siete fallos de disco pero tiene menor capacidad y eficiencia de almacenamiento.
El RAID 50 mejora el rendimiento del RAID 5, especialmente en escritura, y proporciona mejor tolerancia a fallos que un nivel RAID único. Este nivel se recomienda para aplicaciones que necesitan gran tolerancia a fallos, capacidad y rendimiento de búsqueda aleatoria.
A medida que el número de unidades del conjunto RAID 50 crece y la capacidad de los discos aumenta, el tiempo de recuperación lo hace también.

Niveles RAID propietarios
Aunque todas las implementaciones de RAID difieren en algún grado de la especificación idealizada, algunas compañías han desarrollado implementaciones RAID completamente propietarias que difieren sustancialmente de todas las demás.Paridad doble
Una adición frecuente a los niveles RAID existentes es la paridad doble, a veces implementada y conocida como paridad diagonal.Como en el RAID 6, hay dos conjuntos de información de chequeo de paridad, pero a diferencia de aquél, el segundo conjunto no es otro conjunto de puntos calculado sobre un síndrome polinomial diferente para los mismos grupos de bloques de datos, sino que se calcula la paridad extra a partir de un grupo diferente de bloques de datos. Por ejemplo, sobre el gráfico tanto el RAID 5 como el RAID 6 calcularían la paridad sobre todos los bloques de la letra A para generar uno o dos bloques de paridad. Sin embargo, es bastante fácil calcular la paridad contra múltiples grupos de bloques, en lugar de sólo sobre los bloques de la letra A: puede calcularse la paridad sobre los bloques de la letra A y un grupo permutado de bloques.De nuevo sobre el ejemplo, los bloques Q son los de la paridad doble. El bloque Q2 se calcularía como A2 xor B3 'xor P3, mientras el bloque Q3 se calcularía como A3 xor P2 xor C1 y el Q1 sería A1 xor B2 xor C3. Debido a que los bloques de paridad doble se distribuyen correctamente, es posible reconstruir dos discos de datos que fallen mediante recuperación iterativa. Por ejemplo, B2 podría recuperarse sin usar ninguno de los bloque x1 ni x2 mediante el cálculo de B3 xor P3 xor Q2 = A2, luego A2 xor A3 xor P1 = A1, y finalmente A1 xor C3 xor Q1 = B2.
No es recomendable que el sistema de paridad doble funcione en modo degradado debido a su bajo rendimiento.

RAID 1.5
RAID 1.5 es un nivel RAID propietario de HighPoint a veces incorrectamente denominado RAID 15. Por la poca información disponible, parece ser una implementación correcta de un RAID 1. Cuando se lee, los datos se recuperan de ambos discos simultáneamente y la mayoría del trabajo se hace en hardware en lugar de en el controlador software.RAID 7
RAID 7 es una marca registrada de Storage Computer Corporation, que añade cachés a un RAID 3 o RAID 4 para mejorar el rendimiento.RAID S o RAID de paridad
RAID S es un sistema RAID de paridad distribuida propietario de EMC Corporation usado en sus sistemas de almacenamiento Symmetrix. Cada volumen reside en un único disco físico, y se combinan arbitrariamente varios volúmenes para el cálculo de paridad. EMC llamaba originalmente a esta característica RAID S y luego la rebautizó RAID de paridad (Parity RAID) para su plataforma Symmetrix DMX. EMC ofrece también actualmente un RAID 5 estándar para el Symmetrix DMX.se complementa de un tripocio de 3,4 megasMatrix RAID
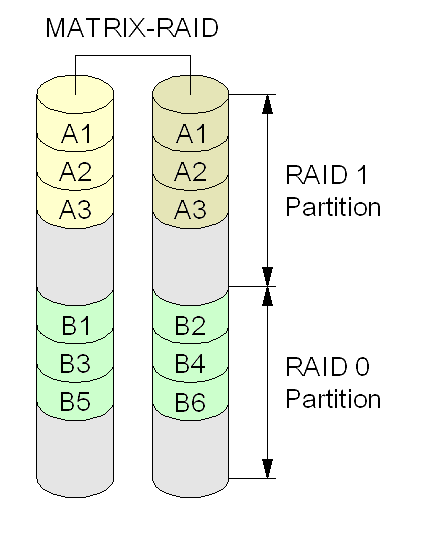
Matrix RAID (‘matriz RAID’) es una característica que apareció por vez primera en la BIOS RAID Intel ICH6R. No es un nuevo nivel RAID. El Matrix RAID utiliza dos o más discos físicos, asignando partes de idéntico tamaño de cada uno de ellos diferentes niveles de RAID. Así, por ejemplo, sobre 4 discos de un total de 600GB, se pueden usar 200 en raid 0, 200 en raid 10 y 200 en raid 5. Actualmente, la mayoría de los otros productos RAID BIOS de gama baja sólo permiten que un disco participen en un único conjunto.Este producto está dirigido a los usuarios domésticos, proporcionando una zona segura (la sección RAID 1) para documentos y otros ficheros que se desean almacenar redundantemente y una zona más rápida (la sección RAID 0) para el sistema operativo, aplicaciones, etcétera.
Linux MD RAID 10
En particular, soporta un espejado de k bloques en n unidades cuando k no es divisible por n. Esto se hace repitiendo cada bloque k veces al escribirlo en un conjunto RAID 0 subyacente de n unidades. Evidentemente esto equivale a la configuración RAID 10 estándar.
Linux también permite crear otras configuraciones RAID usando la controladora md (niveles 0, 1, 4, 5 y 6) además de otros usos no RAID como almacenamiento multirruta y LVM2.

BM ServeRAID 1E
Esta configuración es tolerante a fallos de unidades no adyacentes. Otros sistemas de almacenamiento como el StorEdge T3 de Sun soportan también este modo.

RAID Z
El sistema de ficheros ZFS de Sun Microsystems implementa un esquema de redundancia integrado parecido al RAID 5 que se denomina RAID Z. Esta configuración evita el «agujero de escritura» del RAID 5[1] y la necesidad de la secuencia leer-modificar-escribir para operaciones de escrituras pequeñas efectuando sólo escrituras de divisiones (stripes) completas, espejando los bloques pequeños en lugar de protegerlos con el cálculo de paridad, lo que resulta posible gracias a que el sistema de ficheros conoce la estructura de almacenamiento subyacente y puede gestionar el espacio adicional cuando lo necesita.Posibilidades de RAID
Lo que RAID puede hacer
- RAID puede mejorar el uptime. Los niveles RAID 1, 0+1 o 10, 5 y 6 (sus variantes, como el 50) permiten que un disco falle mecánicamente y que aun así los datos del conjunto sigan siendo accesibles para los usuarios. En lugar de exigir que se realice una restauración costosa en tiempo desde una cinta, DVD o algún otro medio de respaldo lento, un RAID permite que los datos se recuperen en un disco de reemplazo a partir de los restantes discos del conjunto, mientras al mismo tiempo permanece disponible para los usuarios en un modo degradado. Esto es muy valorado por las empresas, ya que el tiempo de no disponibilidad suele tener graves repercusiones. Para usuarios domésticos, puede permitir el ahorro del tiempo de restauración de volúmenes grandes, que requerirían varios DVD o cintas para las copias de seguridad.
- RAID puede mejorar el rendimiento de ciertas aplicaciones. Los niveles RAID 0, 5 y 6 usan variantes de división (striping) de datos, lo que permite que varios discos atiendan simultáneamente las operaciones de lectura lineales, aumentando la tasa de transferencia sostenida. Las aplicaciones de escritorio que trabajan con ficheros grandes, como la edición de vídeo e imágenes, se benefician de esta mejora. También es útil para las operaciones de copia de respaldo de disco a disco. Además, si se usa un RAID 1 o un RAID basado en división con un tamaño de bloque lo suficientemente grande se logran mejoras de rendimiento para patrones de acceso que implique múltiples lecturas simultáneas (por ejemplo, bases de datos multiusuario).
Lo que RAID no puede hacer
- RAID no protege los datos. Un conjunto RAID tiene un sistema de ficheros, lo que supone un punto único de fallo al ser vulnerable a una amplia variedad de riesgos aparte del fallo físico de disco, por lo que RAID no evita la pérdida de datos por estas causas. RAID no impedirá que un virus destruya los datos, que éstos se corrompan, que sufran la modificación o borrado accidental por parte del usuario ni que un fallo físico en otro componente del sistema afecten a los datos.
- RAID no simplifica la recuperación de un desastre. Cuando se trabaja con un solo disco, éste es accesible normalmente mediante un controlador ATA o SCSI incluido en la mayoría de los sistemas operativos. Sin embargo, las controladoras RAID necesitan controladores software específicos. Las herramientas de recuperación que trabajan con discos simples en controladoras genéricas necesitarán controladores especiales para acceder a los datos de los conjuntos RAID. Si estas herramientas no los soportan, los datos serán inaccesibles para ellas.
- RAID no mejora el rendimiento de todas las aplicaciones. Esto resulta especialmente cierto en las configuraciones típicas de escritorio. La mayoría de aplicaciones de escritorio y videojuegos hacen énfasis en la estrategia de buffering y los tiempos de búsqueda de los discos. Una mayor tasa de transferencia sostenida supone poco beneficio para los usuarios de estas aplicaciones, al ser la mayoría de los ficheros a los que se accede muy pequeños. La división de discos de un RAID 0 mejora el rendimiento de transferencia lineal pero no lo demás, lo que hace que la mayoría de las aplicaciones de escritorio y juegos no muestren mejora alguna, salvo excepciones. Para estos usos, lo mejor es comprar un disco más grande, rápido y caro en lugar de dos discos más lentos y pequeños en una configuración RAID 0.
- RAID no facilita el traslado a un sistema nuevo. Cuando se usa un solo disco, es relativamente fácil trasladar el disco a un sistema nuevo: basta con conectarlo, si cuenta con la misma interfaz. Con un RAID no es tan sencillo: la BIOS RAID debe ser capaz de leer los metadatos de los miembros del conjunto para reconocerlo adecuadamente y hacerlo disponible al sistema operativo. Dado que los distintos fabricantes de controladoras RAID usan diferentes formatos de metadatos (incluso controladoras de un mismo fabricante son incompatibles si corresponden a series diferentes) es virtualmente imposible mover un conjunto RAID a una controladora diferente, por lo que suele ser necesario mover también la controladora. Esto resulta imposible en aquellos sistemas donde está integrada en la placa base. Esta limitación puede obviarse con el uso de RAID por software, que a su vez añaden otras diferentes (especialmente relacionadas con el rendimiento).
No hay comentarios:
Publicar un comentario